Loading content...
HAVE A QUESTION?
Call us : +1-945-209-7691
Web scraping is the process of extracting data from websites, making it a powerful tool for gathering information at scale. Learn how to use Python libraries like BeautifulSoup and Selenium to automate data collection effectively.
Automated scraping reduces manual data gathering efforts drastically.
Convert unstructured web content into clean, usable datasets.
Understand ethical scraping and respect robots.txt for compliance.
Loading content...
Let's discuss your project and create a custom web application that drives your business forward. Get started with a free consultation today.






Web scraping is the process of extracting data from websites, making it a powerful tool for gathering information for research, analysis, and application development. Whether you’re collecting market trends, monitoring competitors, or automating data entry, web scraping can save time and effort.
Python is one of the most popular programming languages for web scraping, thanks to its simplicity and a vast ecosystem of libraries like BeautifulSoup, Requests, Selenium, and Scrapy.
In this blog, we’ll walk you through the fundamentals of web scraping using Python, covering everything from setting up your environment to extracting data efficiently — all in a beginner-friendly manner.
Web scraping is an automated technique used to extract data from websites using code. Instead of manually copying information, web scraping enables you to gather data efficiently and systematically. It acts like a virtual assistant that browses websites and collects the required information in a structured format, saving both time and effort.
Web scraping is widely used for automating data collection and analysis. Here are some key reasons why it’s beneficial:
Automates Data Collection — Saves time by extracting large amounts of data quickly.
Cost-Effective — Reduces the need for manual data entry, lowering operational costs.
Competitive Advantage — Helps in market research, price comparison, and competitor analysis.
Real-Time Data Gathering — Enables businesses to track trends, news, and updates dynamically.
Lead Generation — Extracts potential customer information from online directories and social media.
Sentiment Analysis — Helps analyze customer opinions from reviews and social platforms.
SEO & Content Research — Gathers insights on trending topics, keywords, and backlinks.
Data-Driven Decision Making — Provides valuable insights for businesses and researchers.
Integration with AI & ML — Feeds structured data into machine learning models for better predictions.
Scalability — Can handle large volumes of data, making it useful for big data applications.
While scraping publicly available data is generally acceptable, scraping private or protected data without permission can lead to legal consequences. Always check a website’s robots.txt file to understand the scraping policies.
Python is one of the most popular programming languages for scraping due to its simplicity and ecosystem. The primary tools available in Python for web scraping are:
Powerful Libraries — Tools like BeautifulSoup, Scrapy, and Selenium streamline scraping.
Handles Dynamic Content — Scrapes JavaScript-heavy websites using Selenium or Playwright.
Great Data Processing — Works well with Pandas and NumPy for data analysis.
Automation & Scheduling — Can automate tasks with cron jobs or schedulers.
Python’s flexibility, scalability, and ease of use make it the best choice for web scraping.
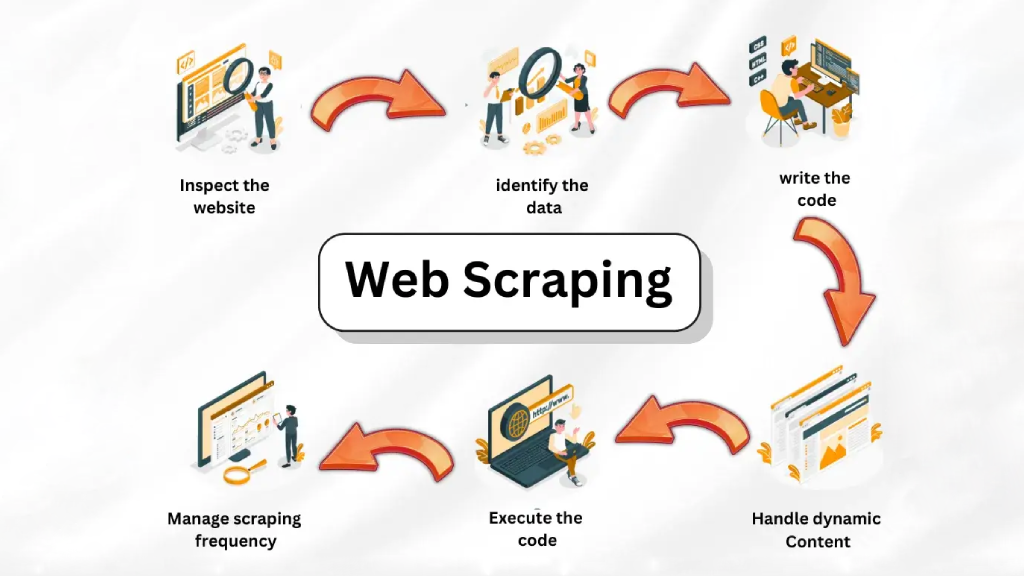
Web scraping involves a number of steps, including:
The first step in web scraping is to identify the website you want to scrape. This could be a website that you are interested in, or a website that you need to scrape for work.
Once you have identified the website you want to scrape, you need to find the data you want to extract. This could be anything from product prices to news articles.
The next step is to write a script to extract the data. This script will need to be able to:
Identify the HTML elements that contain the data you want to extract.
Extract the data from these elements.
Store the data in a file or database.
The final step is to store the extracted data in a usable format, such as a CSV file or a database.
Before you begin, ensure you have Python installed on your system. You can download it from python.org.
Next, install the libraries we’ll use for scraping:
1
pip install requests beautifulsoup4 lxmlrequests — Sends HTTP requests to retrieve webpage content.
BeautifulSoup — Parses raw HTML data and helps extract specific elements (e.g., titles, links, tables).
lxml — A high-speed parser used by Beautiful Soup for processing HTML efficiently.
Let’s scrape a simple website to extract data. Below is a Python script to scrape quotes from the “Quotes to Scrape” website.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Step 1: Fetch the webpage
url = "https://quotes.toscrape.com/" # Real website for practicing web scraping
response = requests.get(url)
# Step 2: Check if the request was successful
if response.status_code == 200:
html_content = response.text
else:
print("Failed to retrieve the webpage.")
exit()
# Step 3: Parse the HTML content
soup = BeautifulSoup(html_content, 'lxml')
# Step 4: Extract the desired data (quotes and authors)
quotes = soup.find_all('span', class_='text') # Extract quotes
authors = soup.find_all('small', class_='author') # Extract authors
# Step 4.1: Print the extracted data
print("Quotes and Authors:")
for quote, author in zip(quotes, authors):
print(f'"{quote.get_text()}" - {author.get_text()}"')
# Step 5: Store the extracted data in a DataFrame
data = {
"Quote": [quote.get_text() for quote in quotes],
"Author": [author.get_text() for author in authors]
}
df = pd.DataFrame(data)
# Step 6: Save the data to a CSV file
df.to_csv("quotes_scraped.csv", index=False, encoding="utf-8")
print("Data successfully saved to 'quotes_scraped.csv'.")Let’s understand the example above.
Fetching the Webpage: We use the requests library to send an HTTP request and retrieve the webpage content.
The script uses requests.get(url) to retrieve the HTML content from https://quotes.toscrape.com/.
1
2
3
# Step 1: Fetch the webpage
url = "https://quotes.toscrape.com/" # Real website for practicing web scraping
response = requests.get(url)Checking the Response Status: If response.status_code == 200, the HTML content is extracted; otherwise, the script exits.
Parsing the HTML: BeautifulSoup helps us extract useful data from the HTML content.
BeautifulSoup html_content, 'lxml' processes the raw HTML using the lxml parser, which is fast and efficient.
1
2
3
from bs4 import BeautifulSoup
# Step 3: Parse the HTML content
soup = BeautifulSoup(html_content, 'lxml')Extracting Specific Data:
soup.find_all('span', class_='text') finds all quotes within < span > tags.
soup.find_all('small', class_='author') finds author names within < small > tags.
1
2
3
# Step 4: Extract the desired data (quotes and authors)
quotes = soup.find_all('span', class_='text') # Extract quotes
authors = soup.find_all('small', class_='author') # Extract authorsStoring Scraped Data:
Extracted data is often saved for further use. You can write the results to a CSV file like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
import pandas as pd
# Step 5: Store the extracted data in a DataFrame
data = {
"Quote": [quote.get_text() for quote in quotes],
"Author": [author.get_text() for author in authors]
}
df = pd.DataFrame(data)
# Step 6: Save the data to a CSV file
df.to_csv("quotes_scraped.csv", index=False, encoding="utf-8")
print("Data successfully saved to 'quotes_scraped.csv'.")Respect robots.txt: Check the website’s robots.txt file to see if scraping is allowed.
Use Headers and User Agents: Some websites block bots. Bypass this by setting a custom user-agent.
Avoid Overloading the Server: Use delays like time.sleep() to prevent making too many requests in a short period.
Handle Exceptions and Errors: Websites may change structure; always write code that handles exceptions gracefully.
Web scraping with Python is a powerful tool for data collection. By combiningrequests,BeautifulSoup, andSelenium, you can extract and structure data from the web efficiently. Always follow ethical practices and respect website policies to avoid legal issues.
