Building AI Assistants with Ollama and n8n — Local, Private, and Automated
Every CTO I meet asks the same two questions: How can we ship AI features quickly without leaking data to the cloud? And how do we keep costs predictable as usage grows?
Hosted LLMs are excellent for prototyping, but they come with trade-offs: ongoing token costs, compliance risks, and vendor lock-in.
Another path gaining traction is running a Local AI assistant with Ollama, orchestrated via the n8n workflow builder.
The result is a private LLM under your control, integrated with your systems, deployable on a laptop, server, or in your data center.
In this article, we explain what Ollama and n8n do, why they work well together, and provide a step-by-step workflow:
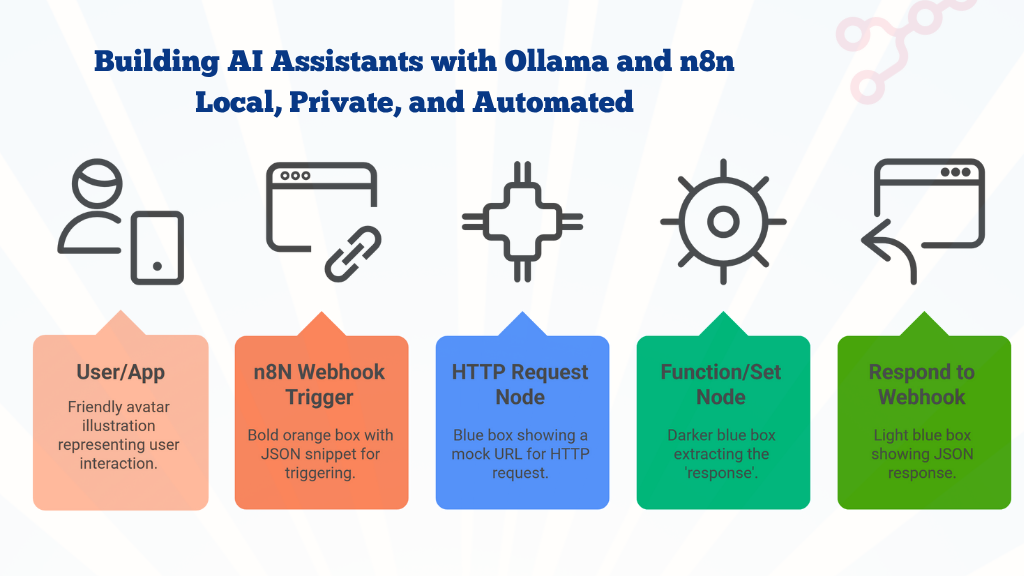
user query → n8n webhook → Ollama API → AI response → return to user
We'll also cover real-world use cases, architecture tips, and common pitfalls, helping you move from idea to production-ready prototype.
What Is Ollama? A Local LLM Runner You Control
Ollama is a lightweight, open-source runtime for large language models (LLMs) that runs locally or on your servers.
It functions as a local LLM engine with a simple API.
Models like Llama 3, Mistral, Qwen, and Phi-3 can be pulled with a single command, while Ollama handles quantization, GPU/CPU acceleration, and streaming responses.
Why teams choose Ollama:
Privacy by default: Prompts and data never leave your environment
Predictable cost: No per-token API charges; use your existing hardware
Flexibility: Swap models, run multiple models, or pin versions
Simplicity: Clean REST API and CLI that just works
It's the backbone of a private LLM strategy. For regulated data, it's the easiest way to start self-hosted AI.
What Is n8n? The Open-Source Automation Engine for Builders
n8n is a self-hosted automation platform—similar to Zapier but fully customizable.
Its visual workflow builder connects triggers (webhooks, Cron, queues) with actions (HTTP requests, databases, Slack, Gmail, Jira, and more).
Why n8n fits AI workflows:
It's the glue: Orchestrates data in and out of your LLM
Runs anywhere: Docker, Kubernetes, or a small VM
Extensible: Code nodes, custom functions, and community packages
Governance: Logs stay in your environment for AI privacy and compliance audits
Together, Ollama + n8n form a complete on-prem AI workflow stack: local inference paired with automation across your systems.
Why Ollama + n8n Belongs on Your Roadmap for On-premises AI Workflows
Local AI infra combined with automation isn't just a cost play—it's a strategy for control, resilience, and scalability.
Key benefits:
Privacy & security compliance: Keep prompts, documents, and user data inside your VPC or data center. Easily meet SOC 2, HIPAA, or internal security requirements.
Cost Efficiency: Avoid Escalating API Costs: Once your hardware is in place, Ollama's marginal cost per request trends toward zero.
Reliability: Eliminate dependence on external APIs, vendor outages, or rate limits. You control the stack—and your SLAs.
Speed to value: n8n's nodes and expressions let you prototype in hours and ship in days.
Future-proofing: Swap models as they improve or add retrieval augmentation later, without requiring workflow changes.
Zero external dependency: Retain full AI capabilities while keeping sensitive data local.
Insights:
Local AI Execution: Run your AI assistant entirely on your own infrastructure—no data leaves your environment.
Full Data Control: Keep all prompts, documents, and user information private, meeting internal security or compliance needs.
Automated Workflows: Use n8n to create simple, no-code automations that streamline tasks across systems.
Private AI Endpoint: Integrate your AI assistant into any system without exposing data to the cloud.
Custom AI Assistant: Build an assistant that understands your data, responds intelligently, and adapts to your workflow.
What You'll Build
Private API Endpoint: You'll create an endpoint that listens to user questions and replies with AI-generated answers — powered entirely by Ollama running locally.
Workflow Overview: User → n8n Webhook → Ollama API → Response Back
Example Prompt: "Summarize our Q2 roadmap in two bullet points."
Response Handling: Your local Ollama model generates a response, and n8n sends it back as structured JSON.
Prerequisites
Before we dive in, make sure you have these ready:
Ollama Installed and Running : Ollama is a local LLM runtime that lets you run models like Llama 3, Mistral, Phi-3, and more on your machine. Default API port: 11434Install and pull a model (e.g., Llama 3): ollama pull llama3:8b
n8n Installed and Running : n8n is an automation tool that can run locally or in Docker. It lets you connect APIs, process data, and automate tasks without coding. You can use either a local install or a Docker container.
Once both are up, we're ready to connect them.
Step-by-Step Setup: n8n Webhook → Ollama API → Response
Let's build this workflow from scratch in n8n.
Step 1: Create a Webhook Trigger
This is your AI assistant's entry point — the URL where users or apps send their questions.
Add a Webhook node in n8n.
Set:
Method: POST
Path: /ask
Response Mode: On Received
JSON input:
1
{ "prompt": "Your question here" }
Now, you have a webhook URL like:
https://your-n8n-host/webhook/ask
This acts as your assistant's public (or internal) endpoint.
Step 2: Connect to Ollama via HTTP Request Node
Next, add an HTTP Request node that calls Ollama's local API.
You can test it right away using curl or any HTTP client (like Postman):
1
2
3
curl -X POST https://your-n8n-host/webhook/ask \
-H "Content-Type: application/json" \
-d '{"prompt":"Summarize our Q2 roadmap in two bullet points."}'
Behind the scenes, this happens:
n8n receives the prompt via webhook
Sends it to Ollama (http://localhost:11434/api/generate)
Ollama runs the model and returns: - Launch EU region - Expand partner integrations
n8n sends that clean response back to you.
You've just built a fully private AI endpoint.
Real-World Use Cases You Can Ship This Week
Auto-summarize documents: Drop a PDF into a folder or S3 bucket. n8n detects the file, extracts text (e.g., via a PDF node), and sends it to Ollama for summarization. Output can go to Slack, email, or a knowledge base.
Draft emails or support replies: Connect n8n to your help desk. When a ticket arrives, n8n gathers context and asks Ollama to draft a reply. Include system prompts for brand voice and compliance rules. Agents can review before sending, ensuring AI privacy and security.
Private chat assistants for internal use: Build a secure chat UI that posts to your n8n webhook. Add retrieval: n8n fetches relevant content from Confluence or a vector database and sends it with the prompt to your Private LLM. Ideal for policy Q&A, dev onboarding, and internal SOPs.
Meeting notes → actionable tasks: Capture transcripts from Zoom or Teams. n8n summarizes via Ollama, then creates tasks in Jira, Asana, or GitHub.
Data cleanup and enrichment: For CSVs or CRM entries, n8n parses rows and calls Ollama to normalize fields, classify intent, or extract entities. Push cleaned data back to your database or analytics pipeline.
Security review assistant: Feed internal policy documents to a retrieval layer. Ask Ollama to evaluate proposed changes against policy and highlight gaps.
Choosing Models and Designing for Scale
Not every model fits every task. Start pragmatic, then iterate as needs evolve.
Modern CPUs can run quantized 7B models for low-throughput tasks.
A single prosumer GPU (e.g., 24 GB VRAM) can serve 7B–13B models for team-scale workloads.
Quantization reduces memory usage with minimal quality loss for many tasks.
Architecture Patterns:
Retrieval-Augmented Generation (RAG): Use n8n to pull relevant documents or vectors before calling Ollama. Pass the snippets with the prompt for grounded answers.
Prompt templates & system prompts: Standardize tone, compliance, and formatting. Store them in n8n credentials or environment variables.
Caching: Cache frequent answers or embeddings to reduce load.
Streaming: For chat UIs, set "stream": true to reduce perceived latency.
Observability: Log prompt and response metadata for QA and iteration—without storing sensitive content unless necessary.
Common Pitfalls and How to Avoid Them
Choosing a model that's too large: Start with 7B–8B. Monitor output quality and scale up only if necessary.
No guardrails: Always include a system prompt with rules (e.g., “If unsure, ask for clarification”) to reduce hallucinations.
Ignoring timeouts and retries: Configure timeouts in n8n HTTP nodes and implement retries with backoff to handle transient load.
Logging sensitive data: Redact fields or avoid storing raw prompts/responses. Scrub data in a Function node before persisting.
Neglecting dependency isolation: Use Docker or containers to pin model versions and isolate services.
Poor networking setup: In Docker, ensure n8n and Ollama share a network. Use service names instead of localhost.
Skipping evaluation: Maintain a small test set of prompts and expected outputs. Track accuracy and hallucination rates like any other product metric.
From Prototype to Production with Moltech
If you're thinking, “We can ship this in a week,” you're not wrong.
The stack is mature, the tools are open-source, and the path from idea to impact is short.
Moltech specializes in open-source AI integration and AI-powered automation. We design on-prem AI workflows, build n8n automations around the Ollama API, and implement safeguards for privacy and security.
Whether you're piloting a Local AI assistant, designing a retrieval layer, or scaling on-prem AI workflows across teams, we can help.
Explore Moltech AI Integration Services to architect your stack.
Visit Moltech Automation Consulting to move from prototype to production.
For regulated environments, see Moltech Security-by-Design AI for hardened workflows, auditability, and compliance support.
Conclusion: Private, Powerful, and Ready for Your Roadmap
Ollama provides a private LLM engine, and n8n delivers orchestration.
Together, they enable on-prem AI workflows that are fast to build, safe to run, and cost-effective to scale.
Automate document summaries, draft support replies, and deploy internal chat assistants—all without sending data to external APIs.
If you're serious about Local AI assistants and n8n automation, now is the time to act.
Start with the simple webhook-to-Ollama pattern, layer in retrieval as needed, and harden security as you grow.
When you're ready for design reviews, performance tuning, or a full production rollout, Moltech is ready to guide you every step of the way.
👉At Moltech, we help you run private LLMs securely with Ollama. Our team designs on-prem AI systems that balance speed, compliance, and control. Explore Secure On-Prem AI Deployment and Edge AI Architecture with us today.
Costs depend on your hardware and integration scope. With no per-token cloud fees, operational costs stay low after setup. Moltech offers flexible consulting packages tailored to your budget.
All data remains within your environment, meeting compliance for SOC 2 or HIPAA. Security measures include key management, network isolation, and audit logging for full governance.
Yes. Ollama scales with GPUs and container orchestration, and n8n can cluster for higher loads. Combined, they enable scalable private AI for enterprise-grade use.
You can prototype in days and deploy in weeks. Moltech accelerates delivery through secure architecture design, workflow automation, and model integration.
Use cases include document summarization, internal chatbots, automated email drafting, meeting notes to tasks, and AI-driven data cleanup — all running privately on your infrastructure.
We implement RAG architectures, prompt templates, and guardrails, plus testing and evaluation pipelines to ensure consistent, factual outputs from your AI assistants.
Yes. Moltech provides full-stack AI integration, deployment, and compliance support for regulated industries needing audit-ready AI workflows.
Absolutely. n8n’s integrations connect easily with CRMs, databases, email systems, and chat tools — embedding private AI directly into your business ecosystem.